Why Bigger Isn’t Always Better: Lessons from Gemini 1.5 Pro's 2M Token Context Window and When to Use RAG
Been playing around with Gemini 1.5 Pro, which packs a 2M token context window. At first, I was like, “Who needs RAG or vector databases when I can just throw everything in there?” Yeah… turns out I was very wrong.
Here’s the catch: more context doesn’t always yield better results 🤯
✅ Fed it highly relevant info (200k-400k tokens) → Amazing results
❌ Threw in some random irrelevant stuff (50/50) → Quality tanked
It’s like trying to have a convo in a noisy room—sure, you can hear everything, but filtering out the noise is a whole other challenge.
Why does this happen?
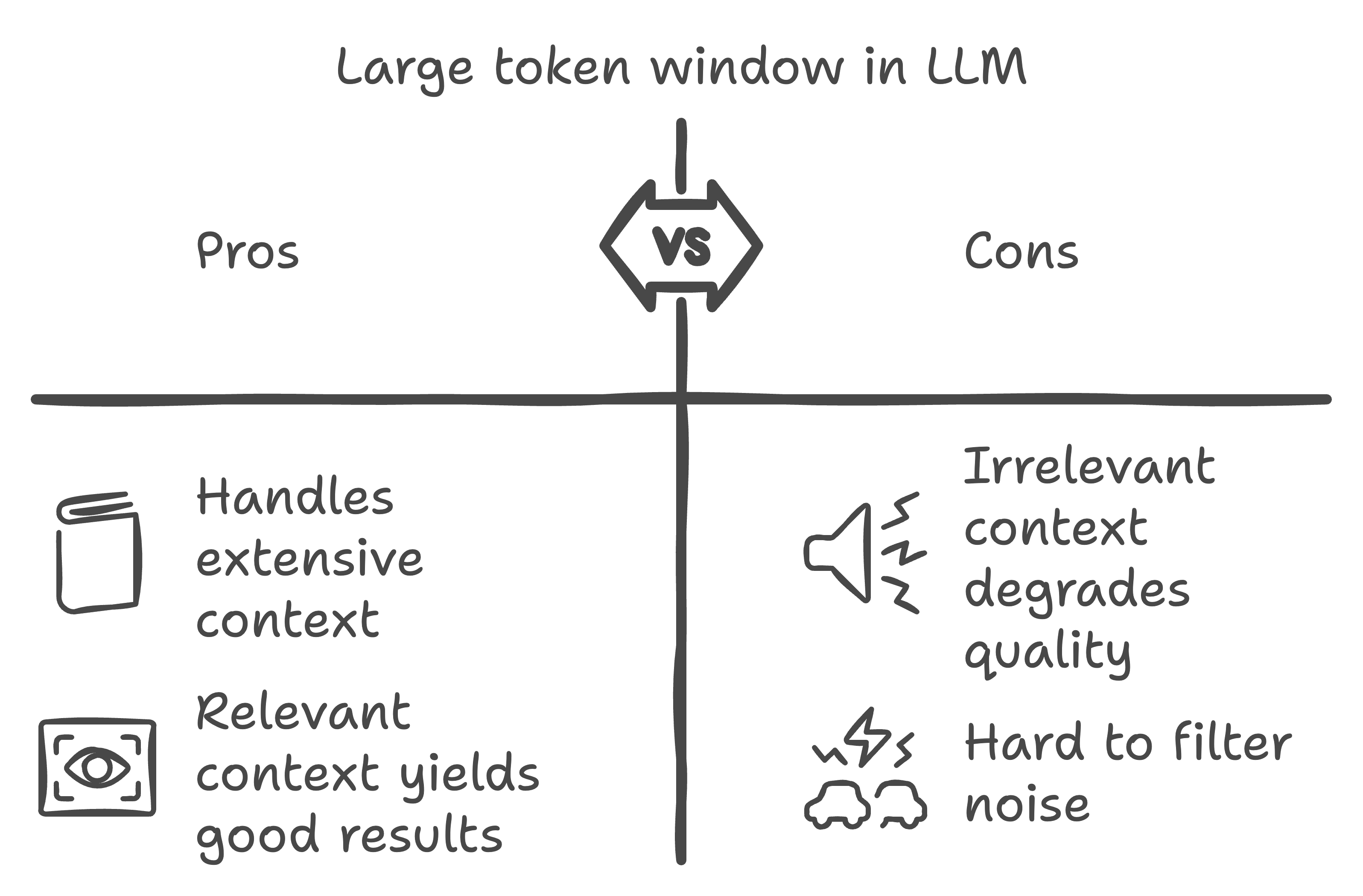
- Noise dilutes signal: Even with a huge token limit, if half the content isn’t relevant, the model struggles to focus on what matters most.
- Relevance > Quantity: LLMs prefer quality input. Sometimes, a smaller but focused dataset performs better than overwhelming the model with long but noisy inputs.
- Positional bias: LLMs tend to give more weight to info that shows up earlier in the input. If key details are buried too deep, the model might just miss them.
- Why not just use the full 2M tokens? Large context window is awesome, but if the input’s a mess, the model gets confused. That’s why RAG still comes in clutch—pulling in only the good stuff and keeping the noise out.
Takeaway:
Just because an LLM can handle 2M tokens doesn’t mean you should dump everything in. Focused, high-quality context always beats sheer quantity.
When I use the large context window to provide all relevant info, the results seem better than with smaller windows (e.g., Claude 100k, GPT-4o 128k, etc.)
However, when the context gets messy or irrelevant, RAG with a good chunking strategy works better—leading to fewer hallucinations or made-up responses.
Sometimes less (but more relevant) is more!